"
"
Team:Oxford/what are microcompartments
From 2014.igem.org
(Difference between revisions)
| Line 40: | Line 40: | ||
<div style="background-color:#D9D9D9; opacity:0.7; z-index:5; Height:75px; width:100%;font-size:65px;font-family:Helvetica;padding-top:5px; font-weight: 450;margin-top:10px;"> | <div style="background-color:#D9D9D9; opacity:0.7; z-index:5; Height:75px; width:100%;font-size:65px;font-family:Helvetica;padding-top:5px; font-weight: 450;margin-top:10px;"> | ||
| - | <div style="background-color:white; opacity:0.9; Height:75px; width:100%;margin-top:5px:margin-bottom:5px;font-size:65px;font-family:Helvetica;padding-top:5px; color:#00000; font-weight: 450;"><br><center><font style="opacity:0.7">What are | + | <div style="background-color:white; opacity:0.9; Height:75px; width:100%;margin-top:5px:margin-bottom:5px;font-size:65px;font-family:Helvetica;padding-top:5px; color:#00000; font-weight: 450;"><br><center><font style="opacity:0.7">What are they?</font></center></div> |
</div> | </div> | ||
<br> | <br> | ||
Revision as of 22:22, 11 October 2014

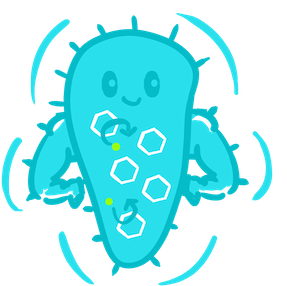



 Microcompartments are proteinaceous capsules that have only recently been recognised to exist in a wide range of bacteria. They contain enzymes required for a particular metabolic process. The carboxysome is a particularly well-studied example of a specialised microcompartment, and is shown here as a schematic diagram (S. Frank et al, 2013).
Microcompartments are proteinaceous capsules that have only recently been recognised to exist in a wide range of bacteria. They contain enzymes required for a particular metabolic process. The carboxysome is a particularly well-studied example of a specialised microcompartment, and is shown here as a schematic diagram (S. Frank et al, 2013).




 Once treated as ellipsoids, the problem was then reduced to the classical ‘sand packing’ problem. Because the dimensions of these proteins was substantially smaller than the icosahedron (by approximately a factor of 20 in every dimension), we assumed that the geometry of the container i.e. the microcompartment, was not significant.
Once treated as ellipsoids, the problem was then reduced to the classical ‘sand packing’ problem. Because the dimensions of these proteins was substantially smaller than the icosahedron (by approximately a factor of 20 in every dimension), we assumed that the geometry of the container i.e. the microcompartment, was not significant.