 "
"
Team:Oxford/codon optimisation
From 2014.igem.org
Revision as of 13:01, 29 September 2014 by Olivervince (Talk | contribs)
#list li { list-style-image: url("https://static.igem.org/mediawiki/2014/6/6f/OxigemTick.png"); } }











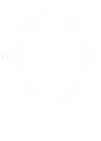





































#list li { list-style-image: url("https://static.igem.org/mediawiki/2014/6/6f/OxigemTick.png"); } }