|
|
| Line 133: |
Line 133: |
| | <div class="white_news_block2"> | | <div class="white_news_block2"> |
| | | | |
| - | <h1>Predicting the mCherry fluorescence</h1> | + | <img src="https://static.igem.org/mediawiki/2014/1/12/Oxford_pSRK-Gm-pdcmAsfGFP_text.png" style="float:left;position:relative; width:100%;" /> |
| - | We simplified the first double repression by modelling it as an activation of <font style="font-style: italic;">dcmR</font> by ATC, albeit parameterised by different constants. This assumption is justified by the fact that we are able to precisely control the addition of ATC and measure the fluorescence of the mCherry.
| + | |
| - | <br>
| + | |
| - | <br>
| + | |
| - | We modelled this first step using both deterministic and stochastic models.
| + | |
| - | </div>
| + | |
| | | | |
| - | <div class="white_news_block2">
| |
| - | <h1>Biochemical equations</h1>
| |
| - | The biochemical equations that describe the behaviour of the top half of the genetic circuit are:
| |
| - |
| |
| - | <img src="https://static.igem.org/mediawiki/2014/f/ff/Oxford_mCherry_circuit2.png" style="float:right;position:relative; width:40%;margin-left:30%;margin-right:30%;" />
| |
| - | <img src="https://static.igem.org/mediawiki/2014/1/1d/Oxford_biochem_equations.png" style="float:right;position:relative; width:80%;margin-left:10%;margin-right:10%;" />
| |
| - | <br>
| |
| - | <br>
| |
| | Oxford iGEM 2014 | | Oxford iGEM 2014 |
| - | </div>
| |
| - |
| |
| - |
| |
| - |
| |
| - |
| |
| - |
| |
| - | <div class="white_news_block2">
| |
| - | <h1>Deterministic</h1>
| |
| - |
| |
| - | <img src="https://static.igem.org/mediawiki/2014/2/2e/Oxford_DcmR_parameters.png" style="float:right;position:relative; height:8%; width:47%;" />
| |
| - |
| |
| - | Deterministic models are very powerful tools for synthetic biology. They describe the behaviour of the bacteria at the population level and use Ordinary Differential Equations (ODEs) to relate each activation and repression. By constructing a cascade of differential equations one can build a realistic model of the average behaviour of the system.
| |
| - | <br>
| |
| - |
| |
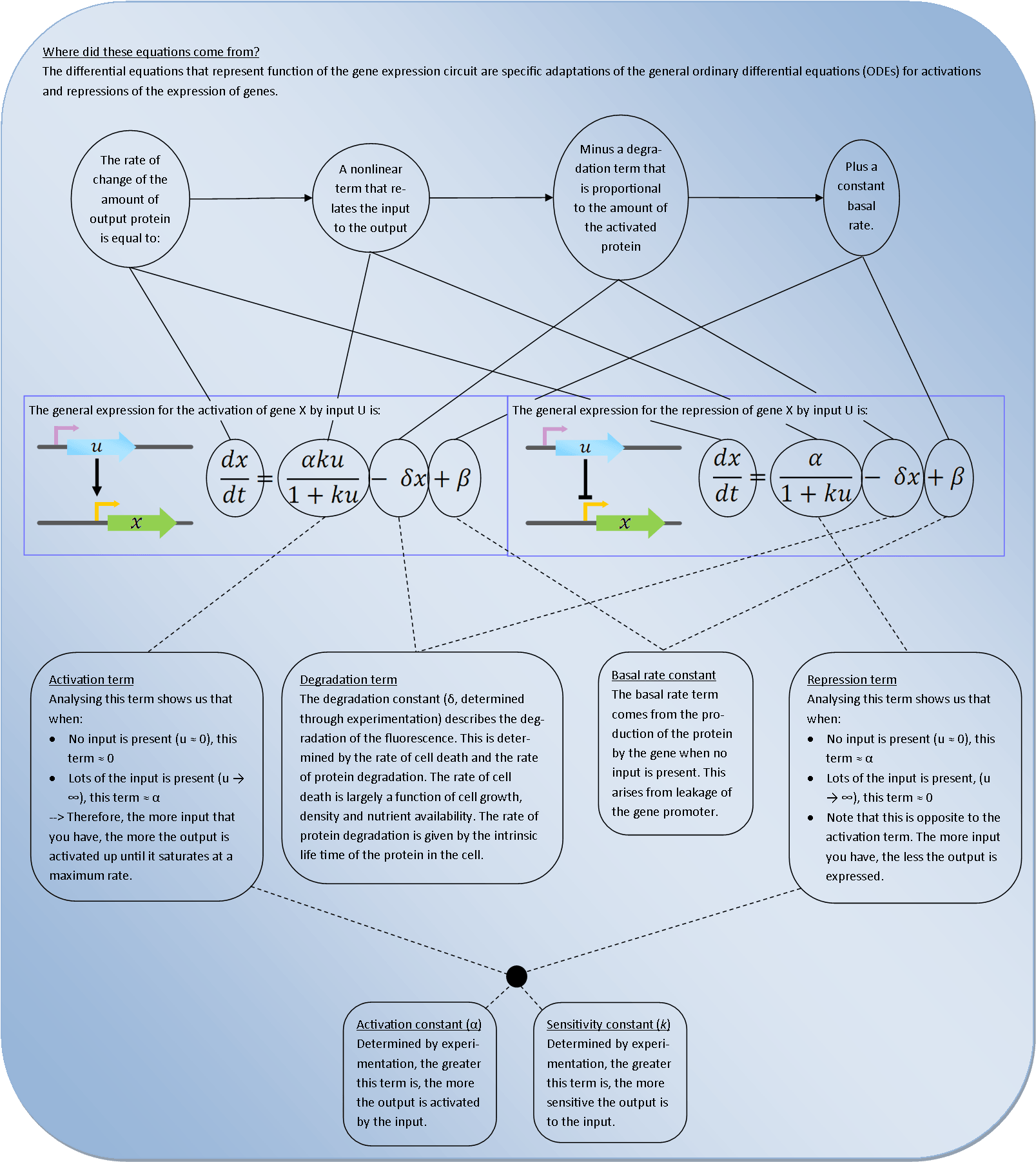
| - | The differential equation that descibes this first step of the system is:
| |
| - |
| |
| - |
| |
| - |
| |
| - | <br><br><img src="https://static.igem.org/mediawiki/2014/e/ed/Oxford_DcmR_activation.png" style="float:left;position:relative; height:8%; width:47%;" />
| |
| - |
| |
| - |
| |
| - |
| |
| - | <br><br><br><br><br>
| |
| - |
| |
| - |
| |
| - | <a href="https://static.igem.org/mediawiki/2014/b/be/Oxford_Equations_explained.png" target="_blank"><img src="https://static.igem.org/mediawiki/2014/4/41/Oxford_equations.png" style="float:left;position:relative; width:40%;" /></a>
| |
| - |
| |
| - | <br><br><br><br><br><br>
| |
| - | Solving this ODE in Matlab <u>(with zero basal transcription rate)</u> predicts the following the response of the system:
| |
| - | <br><br>
| |
| - | This model works assuming that <u>sufficient TetR</u> is always present.
| |
| - | <br><br>
| |
| - | <img src="https://static.igem.org/mediawiki/2014/e/e0/Oxford_MCherry_circuit.png" style="float:left;position:relative; width:40%;" />
| |
| - |
| |
| - | <img src="https://static.igem.org/mediawiki/2014/9/92/MCherry_graph.png" style="float:right;position:relative; width:60%;margin-bottom:3%;" />
| |
| - | Oxford iGEM 2014
| |
| - |
| |
| - | </div>
| |
| - |
| |
| - | <div class="white_news_block2">
| |
| - | While the analysis of this circuit is not critical to the successful outcome of this part of the project, it will provide us with very good practice of both obtaining fluorescence time series data and accurately fitting the data to the model. It will also help us develop our methods of predicting future system behaviour. This is because this system is already well documented in the literature and so we should be able to test our methods and responses against well documented results from labs across the world.
| |
| - | <br><br>
| |
| - | As you can clearly see from the graph, the model predicts a large fluorescence increase as the input is added. This is the what we expect from the actual system and is the best approximation that is obtainable before we get experimental data.
| |
| - | <br><br>
| |
| - | In the graph above, the model is set to have a basal transcription rate of zero. This is why there is a zero fluorescence response before the input has been added - this corresponds to the tetO promoter not being leaky at all. This basal rate will be calibrated alongside all of the other parameters in the model.
| |
| - | </div>
| |
| - |
| |
| - | <div class="white_news_block2">
| |
| - | <h1>Stochastic Modelling</h1>
| |
| - |
| |
| - |
| |
| - | Stochastic modelling uses probability theory to predict the behaviour of a system. For our project, we used it to model the expression of GFP from bacteria.
| |
| - | <br><br>
| |
| - | We started with the Gillespie Algorithm, which considers the expression of GFP to be binary; a molecule of GFP is either produced or degraded. We modelled the probability of a molecule of GFP being created using the Michaelis-Menten model, incorporating a basal transcription rate. For the degradation, we assumed a simple proportional relationship; the more you have the more likely it is that a molecule degrades. The constant of proportionality will be a function of the intrinsic life time of the protein in the cell. Now at every increment in time we will not have a GFP reaction occurring, so before we decided what reaction occurs we had to work out if I a reaction occurred. We did this by writing an equation involving the probability of any reaction occurring with a random number generator. To work out which reaction occurred we compared the relative probability of a production to degradation, and used a random number to make a weighted choice.
| |
| - | <br><br>
| |
| - | We later changed this code so that a reaction occurred every time increment, but included a null reaction where no GFP was degraded or created. Although this made the code a lot more data heavy, it allowed for much easier calculation of the mean response of multiple realisations.
| |
| - | <br><br>
| |
| - | Stochastic modelling is useful because it can show us the stochastic effects which are often seen in real bacteria. By calculating the variation of the mean of multiple GFP producing bacteria, we can also work out the standard deviation. Then if we assume that the system varies with respect to the normal distribution, we can produce error bounds for the production of GFP. Such that we can say, 90% of the time we can expect the production of GFP from a single bacterium to be within these 2 curves. This could be useful for seeing if results are unexpected, or, if there are multiple outliers, that our model is incorrect. If we average more and more bacteria then the mean curve tend towards the deterministic response. This is to be expected as we are now looking at the system as a whole and fluctuations in the production from individual bacteria are averaged out. Sto for small Det for large
| |
| - |
| |
| - | What is stochastic modelling? -- Yes
| |
| - | How is it useful? Ads/Dis -- Getting there
| |
| - | Tending to deterministic -- Yes
| |
| - | Modelling activator repressor --?
| |
| - | Parameter characterisation/Data matching -- Not yet
| |
| - | Matlab graphs – Not yet
| |
| - |
| |
| - | Improve Gillespie algorithm bit
| |
| - |
| |
| - | <li>Matlab graphs</li>
| |
| | | | |
| | </div> | | </div> |
 "
"





 Oxford iGEM 2014
Oxford iGEM 2014
 Oxford iGEM 2014
Oxford iGEM 2014